MAAD is an open-access, curated resource hosting over 27,500 antibody and nanobody entries targeting six major human viruses: SARS-CoV-1, SARS-CoV-2, MERS-CoV, Influenza Virus, RSV, and hMPV. Each entry is annotated with:
Allows users to search MAAD entries using:
Clicking on a search result leads to a detailed entry page with all associated metadata, while clicking on a PDB number or project number (such as PMID or patent ID) directs users to the original source on the respective PDB website or database.
Step 1: Click the right-hand slider to choose a search type

Step 2: Type keywords

The search will match sequences of identical length, leveraging N-Gram indexing and LIKE queries to identify similar or embedded subsequences:
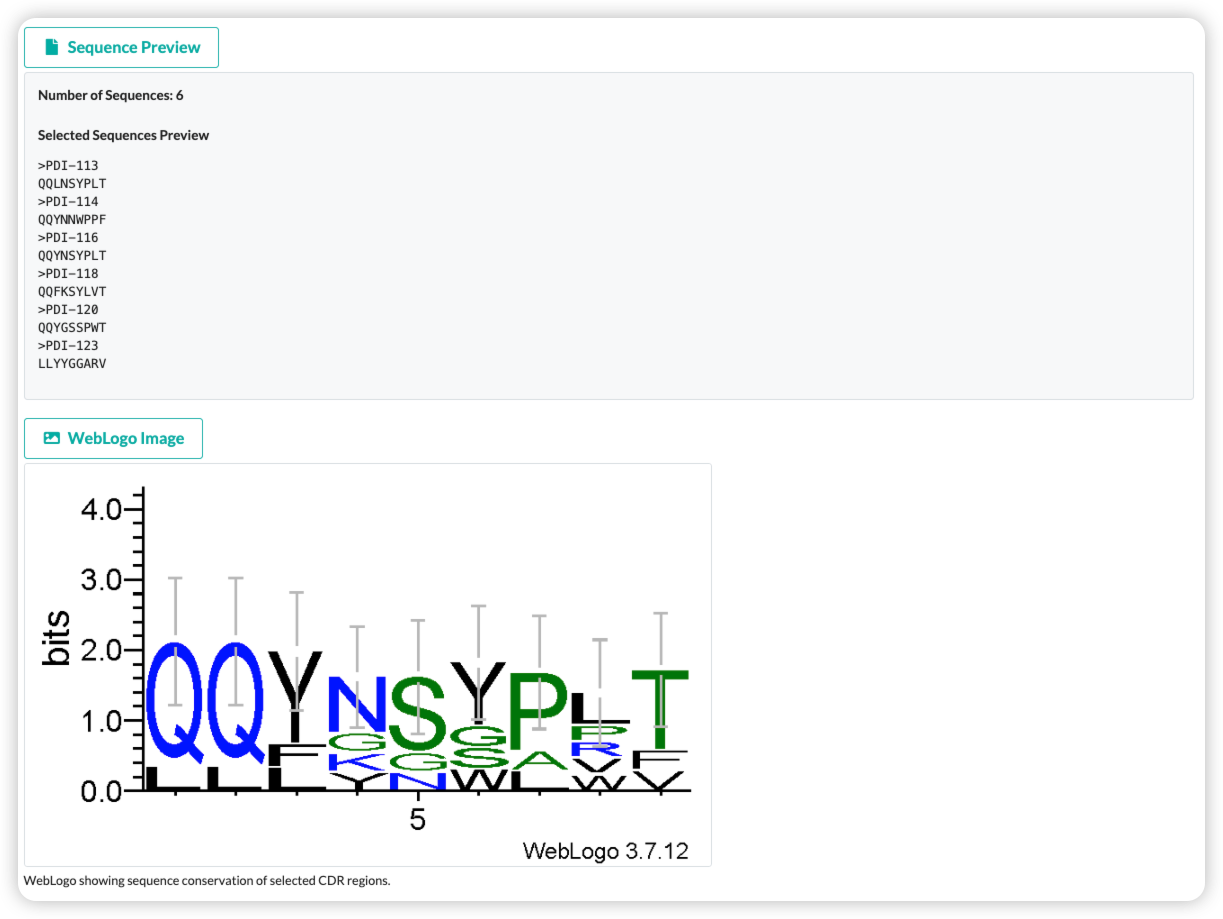
MAAD performs BLAST-based sequence alignment, querying both antibody nucleotide and amino acid sequences against the database:
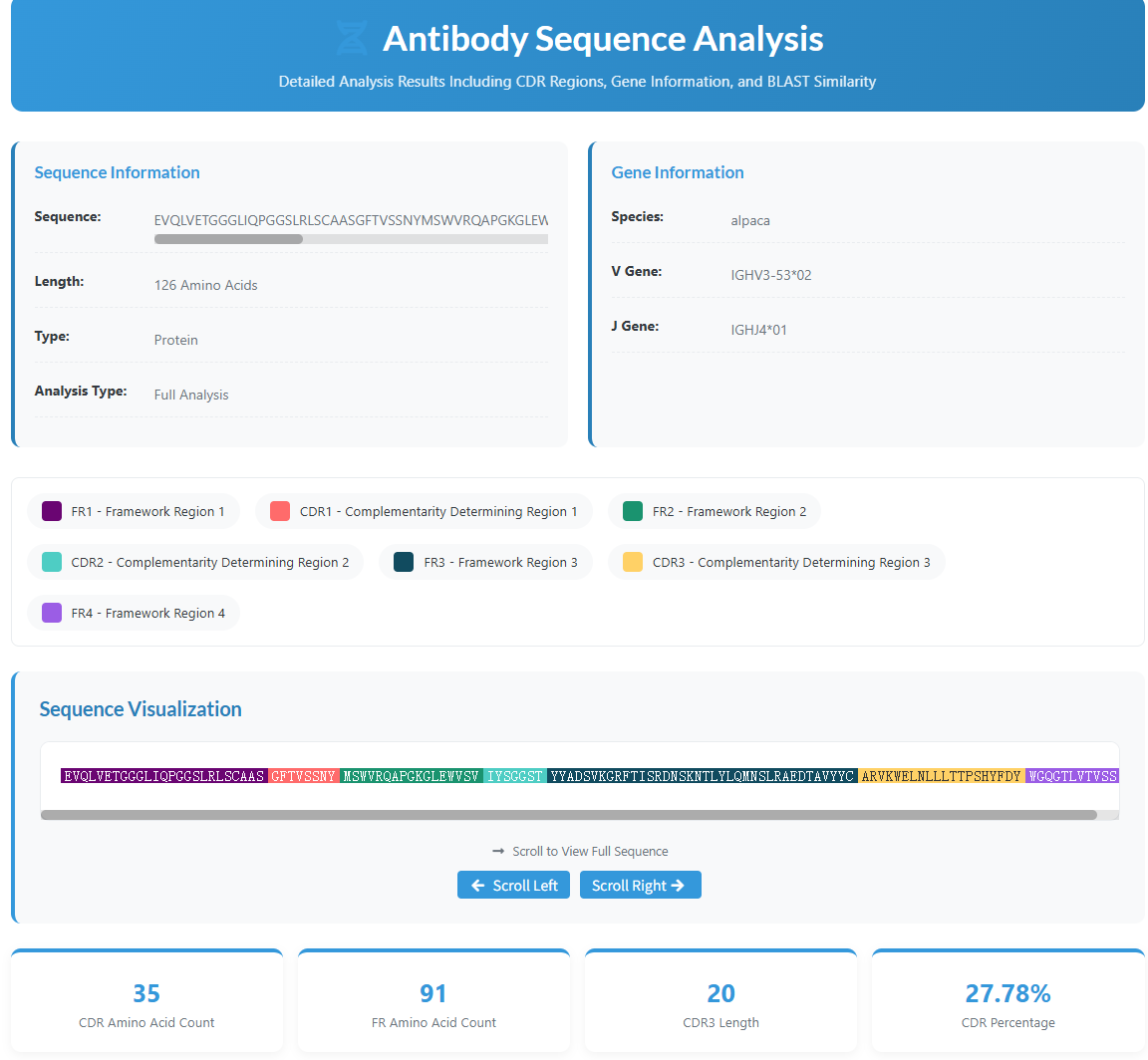
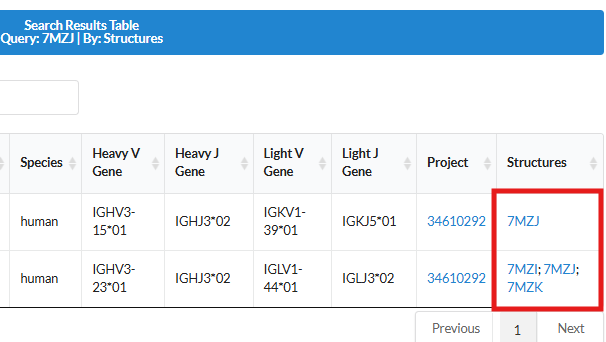
MAAD provides antigen-antibody complex structures with detailed interface annotations and allows direct search by PDB ID on the search page.
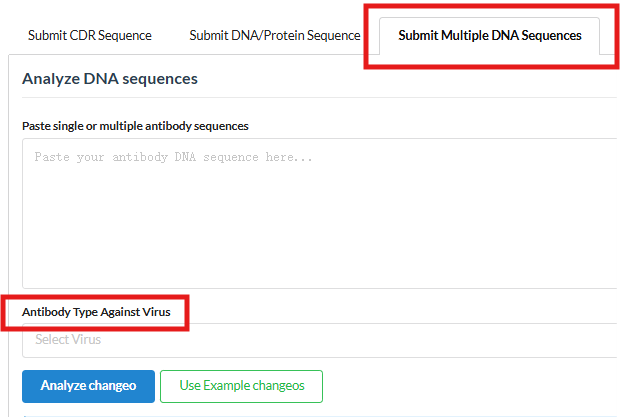
Users can input their own heavy chain nucleotide sequences and select target viral antibody sequences for joint analysis. Results can be downloaded from the results page. Tree construction may take some time, usually less than 3 minutes.
The Download module allows users to export customized or full datasets from MAAD in standardized .xlsx format. For each entry in MAAD, the following data is available for download:
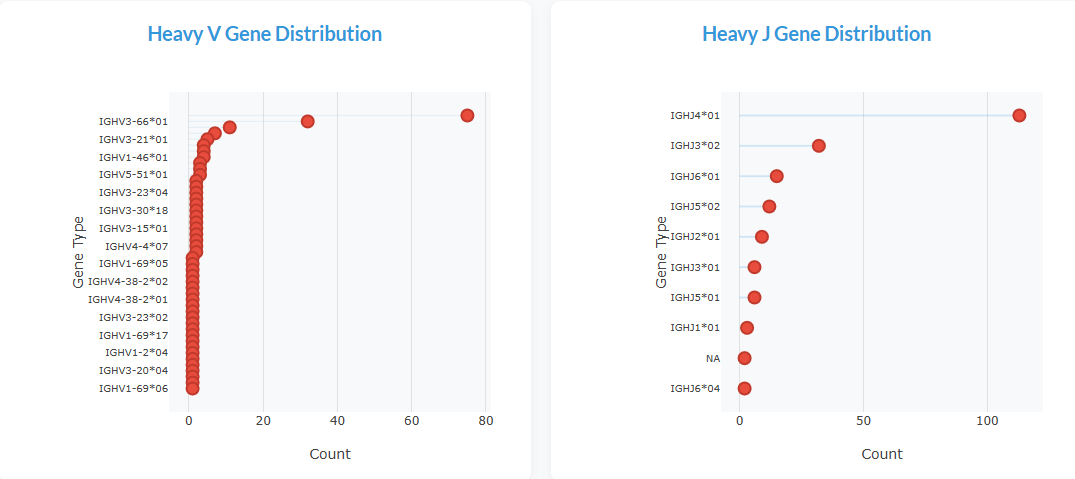
Provides an overview of the MAAD dataset, enabling users to explore key trends and distributions:
For questions, feature requests, or reporting issues, please contact us at:
wangjy@ibp.ac.cn
liyx@ibp.ac.cn
© 2025-2026 All rights reserved.